
简单快速爬取国家统计局数据
准备工作
import requests
import time
import json请预先安装以上库
步骤一、了解报文结构
访问国家统计局数据库网站——国家数据 (stats.gov.cn)。找到你想要爬取的数据并点击,这里我们以GDP为例。
按F12进入控制台,找到“网络”选中Fetch/XHR
刷新界面或单击GDP数据条例,会显示你刚刚发送的报文,选中并点击“负载”标签
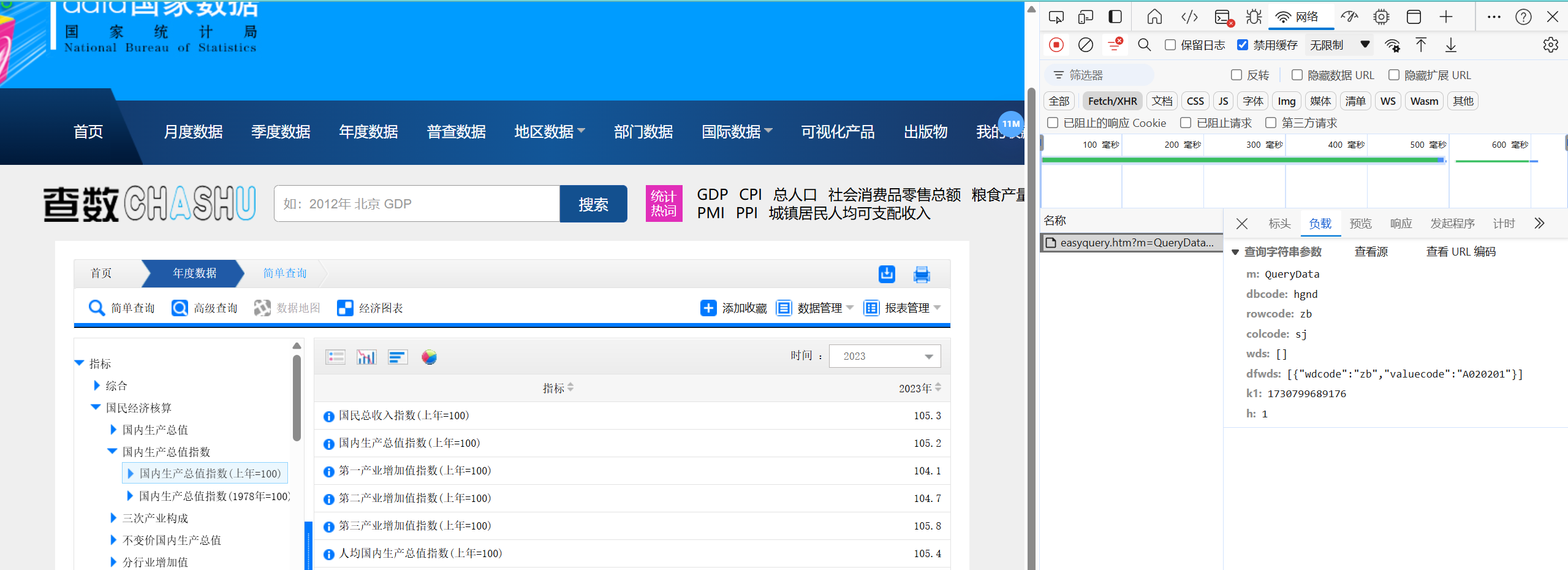
可以看到报文结构如下:
m:QueryData
dbcode:hgnd
rowcode:zb
colcode:sj
wds:[]
dfwds:[{"wdcode":"zb","valuecode":"A020201"}]
k1:1730799689176如果你多点击“国内生产总值指数”你会发现,K1为随机数,是为了防止缓存覆盖,用来刷新数据用的。因此我们需要一个随机数来生成这个K1值(也就是time库)。其他的参数就不需要去管了,就是这个指标的代码。我们需要将这些作为我们的键值对key的值去发送GET请求。
二、数据提取
这里作为一个简单快速教程,就不解释原理,旨在帮助你快速上手。因此我们直接贴出代码:
其中,key中的数据是根据你所需要爬取的数据的参数指标而变的。除此之外,Json报文初始化也是根据爬取的数据而自行设计的,这里不赘述。
import requests
import time
import json
# 生成时间戳函数,用于防止请求缓存
def getTime():
return int(round(time.time() * 1000))
# 请求的URL和请求头信息
url = 'http://data.stats.gov.cn/easyquery.htm?cn=A01'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'
}
# 请求参数键值对
key = {
'm': 'QueryData', # 查询数据的操作
'dbcode': 'hgnd', # 数据库代码
'rowcode': 'zb', # 行代码
'colcode': 'sj', # 列代码
'wds': '[]', # 维度选择
'dfwds': '[{"wdcode":"zb","valuecode":"A020202"},{"wdcode":"sj","valuecode":"2000-2024"}]', # 指标代码
'k1': str(getTime()), # 时间戳,防止缓存覆盖
'h': 1 # 其他参数
}
# 发送HTTP GET请求
r = requests.get(url, headers=headers, params=key)
# 尝试解析响应为JSON格式
try:
js = json.loads(r.text)
# 提取并格式化数据
formatted_data = {}
for node in js['returndata']['datanodes']:
date = node['wds'][1]['valuecode'] # 获取日期值
indicator_code = node['wds'][0]['valuecode'] # 获取指标代码
value = node['data']['strdata'] # 获取数据值
# 初始化日期键
if date not in formatted_data:
formatted_data[date] = {
"date": date,
"GNI": "",
"GDP": "",
"PrimaryIndustry": "",
"SecondaryIndustry": "",
"TertiaryIndustry": "",
"PerCapitaGDP": ""
}
# 根据指标代码将数据添加到格式化数据字典中
if indicator_code == 'A020202':
formatted_data[date]['GNI'] = value # 国民总收入指数
elif indicator_code == 'A02020202':
formatted_data[date]['GDP'] = value # 国内生产总值指数
elif indicator_code == 'A02020203':
formatted_data[date]['PrimaryIndustry'] = value # 第一产业增加值指数
elif indicator_code == 'A02020204':
formatted_data[date]['SecondaryIndustry'] = value # 第二产业增加值指数
elif indicator_code == 'A02020205':
formatted_data[date]['TertiaryIndustry'] = value # 第三产业增加值指数
elif indicator_code == 'A02020206':
formatted_data[date]['PerCapitaGDP'] = value # 人均国内生产总值指数
# 将字典转换为列表格式
formatted_data_list = [values for date, values in formatted_data.items()]
# 打印格式化后的数据
print(json.dumps(formatted_data_list, indent=4, ensure_ascii=False))
# 保存格式化后的数据到本地文件gdp_data.json中
with open('gdp_data.json', 'w', encoding='utf-8') as f:
json.dump(formatted_data_list, f, ensure_ascii=False, indent=4)
except json.JSONDecodeError as e:
print(f"JSON解析错误: {e}")可能的问题
Q:每个指标的indicator_code的值为多少呢?
A:细心的朋友们会发现,这个code的值就是在Key中的‘dfwds’下的valuecode值后面多加01,02,03......。但是需要注意的是,这里是16进制,也就是09的下一个是0A,而0Z的下一个就是10。或者你也可以通过打印原JSON报文来查看对应数据的code值,代码如下:
# print("!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!")
# print(json.dumps(js, indent=4, ensure_ascii=False))
# # 可以查看每个指标的valuecode值这样你就可以直接在终端上看到每个数据的valuecode啦。
阅读建议
