
NSCC NTU注册与连接
一、注册NSCC
访问USER Self- Edit & Register - NSCC and login

选择NTU,并输入账号密码,注意是student.main.ntu.edu.sg后缀的账号
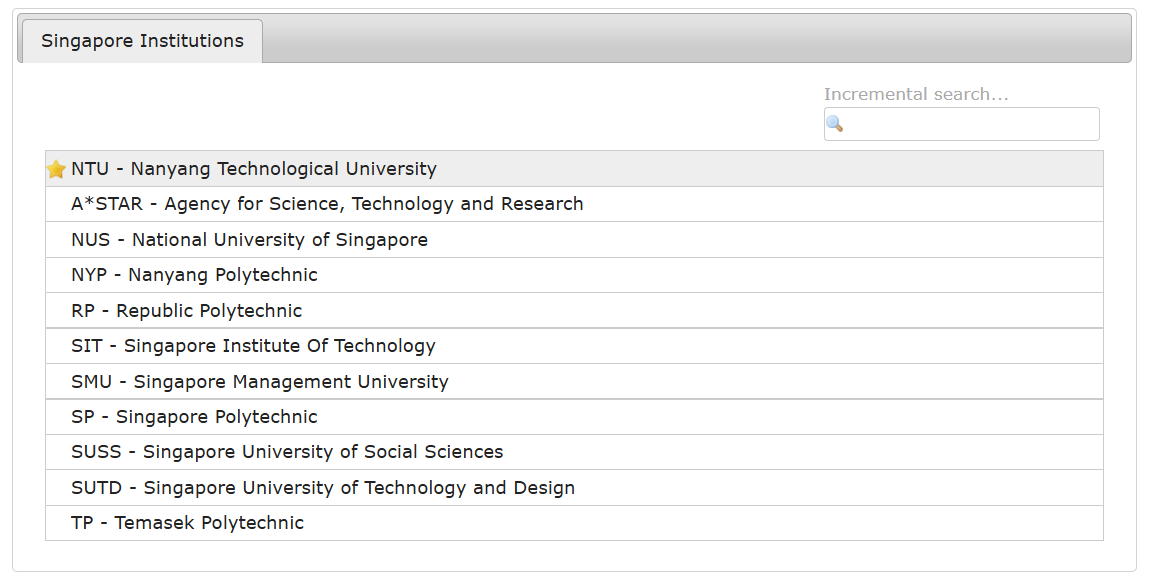
记得reset一下密码,并记住它

二、测试ssh连接
在本地电脑的终端cmd中输入ssh XXX@asp2antu.nscc.sg,其中XXX是你的NSCC账号名
如果连不上port 22: Connection timed out,记得检查网络配置,要连校园网!
密码是刚刚NSCC上set的密码
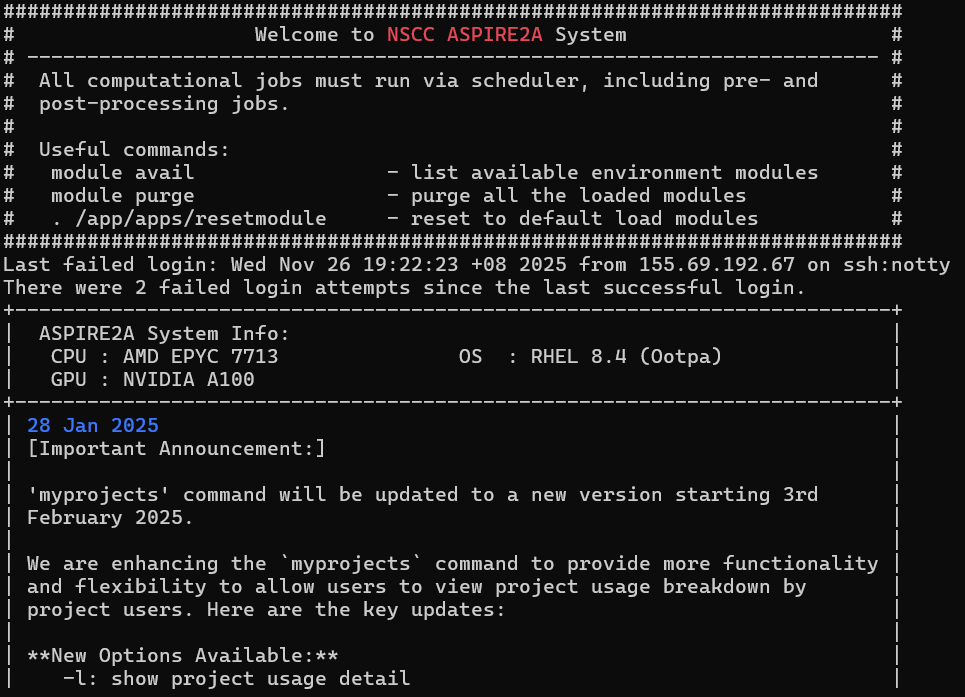
连上后第一次有一个验证,选yes即可。后续连接显示如下就可以了
三、在代码环境中连接
然后来到VScode,安装remote-ssh插件

安装好后在左下角点击按钮进行ssh连接,输入刚刚的ssh XXX@asp2antu.nscc.sg
输入密码后就可以在环境中正常使用了
四、使用
确定 GPU/CPU 资源
终端输入
qstat -Q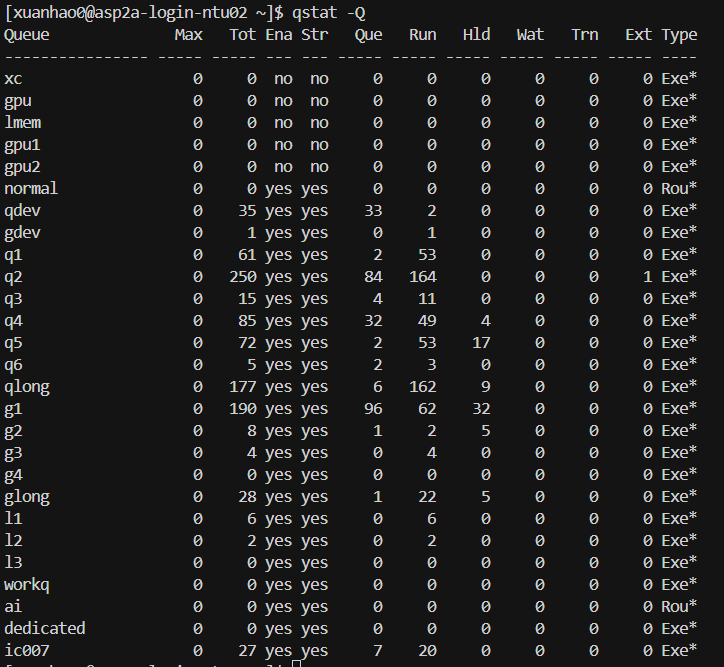
在 PBS / Torque / SLURM 等 HPC 调度系统中,队列就是一类计算资源的集合:
每个队列通常对应一类节点或者资源(CPU、GPU、内存大小等)
你提交作业到某个队列,调度系统会帮你找空闲节点运行
在输出里,常见队列名包括:
输出字段说明
解释:
加载 Python/Conda 环境
NSCC 上不要直接用系统 Python,要用 module 管理器加载软件。
终端输入:
module load miniforge3现在你就拥有了 conda:
# 创建conda虚拟环境
conda create -n myenv python=3.10
conda activate myenv然后可以安装依赖等等。。
编写 PBS 作业脚本
本地的训练代码假设是:
train.py需要在同目录创建:
train_job.pbs示例内容(可直接复制):
#!/bin/bash
#PBS -N pytorch_gpu_job
#PBS -q gpu_v100
#PBS -l select=1:ncpus=4:ngpus=1:mem=32GB
#PBS -l walltime=12:00:00
#PBS -j oe
#PBS -o train_output.log
cd $PBS_O_WORKDIR
module load miniforge3
conda activate myenv
python train.py解释:
提交任务 & 查看状态
提交 PBS 任务
qsub train_job.pbs
成功后会返回:
9418459.pbs101
这就是 Job ID。
查看任务状态
只看自己的任务:
qstat -u $USER状态含义:
查看运行结果
查看日志文件
PBS 会把标准输出合并到你的 .log 或 .oJobID 文件里。
例如:
cat train_output.log或:
cat pytorch_gpu_job.o9418459还能用:
tail -f train_output.log实时查看训练进度(类似 tensorboard 的输出)。
阅读建议
